1. 为什么要使用 mmap
应用程序和驱动程序之间传递数据时,可以通过 read、write 函数进行,如下图:

应用程序不能直接读写驱动程序中的 buffer,需要在用户态 buffer 和内核态 buffer 之间进行一次数据拷贝。这种方式在数据量比较小时没什么问题; 但是数据量比较大时效率太低。例如更新 LCD,假设 LCD 采用 1024 × 600 × 32 bpp 的格式,则一帧数据就有 2.3 M左右,拷贝的步骤效率太低。
应该允许程序直接读写驱动程序中的 buffer,这可以通过 mmap 实现(memory map),把内核的 buffer 映射到用户态,让 APP 在用户态直接读写。
2. 虚拟地址和物理地址
编写一个测试程序:
1 | int a; |
程序运行结果如下:
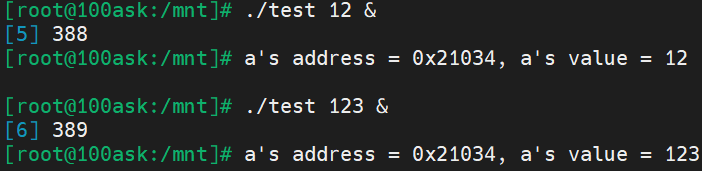
两次运行分别产生了两个进程,打印出来的都是各自进程内变量的虚拟地址。使用cat /proc/进程PID/maps:可以查看进程内划分的不同虚拟内存区域:
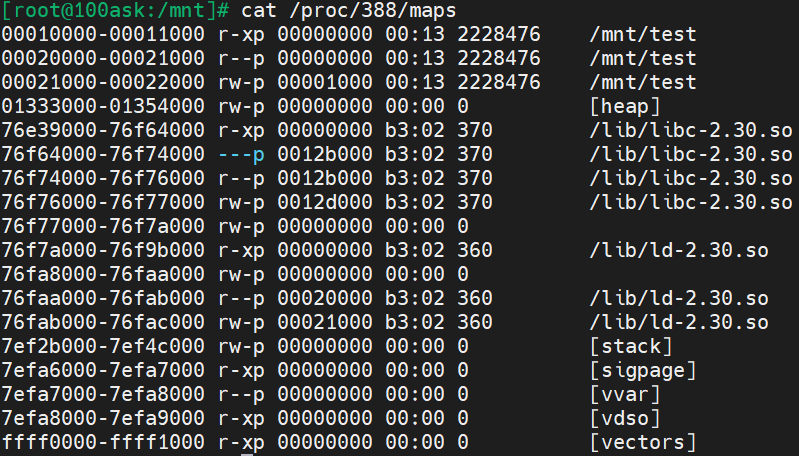
例如第一行是代码段,第二行是只读数据段(data段,存放初始化的全局变量和静态变量),第三行是可读写数据段(bss段,存放的是未初始化的全局变量和静态变量)。
2.1 虚拟地址转换物理地址
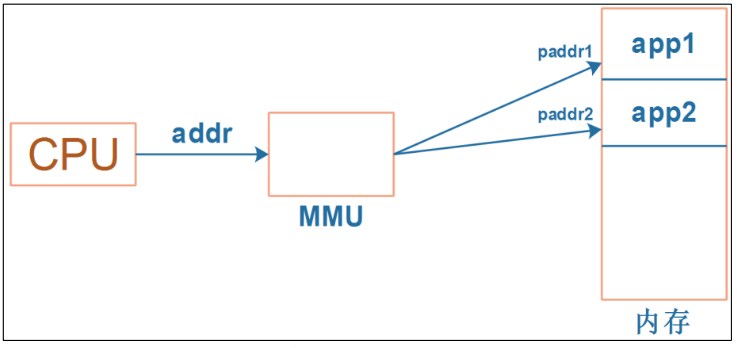
CPU 发出的地址是虚拟地址 ,它经过 MMU(Memory Manage Unit,内存管理单元)映射到物理地址上,对于不同进程的同一个虚拟地址,MMU 会把它们映射到不同的物理地址。如下图:
每一个进程在内核里都有一个 tast_struct,这个结构体中保存有内存信息:mm_struct。而虚拟地址、物理地址的映射关系保存在页目录表中,如下图所示:

- 内存有虚拟地址、物理地址,mm_struct 中用 mmap 来描述虚拟地址,用 pgd (Page Global Directory)来描述对应的物理地址。
- 每个进程都有一系列的 VMA:virtual memory;比如代码段、数据段、BSS 段、栈,共享库等等,内核用一系列 vm_area_struct 来表述
- vm_area_struct 中的 vm_start、vm_end 是虚拟地址,通过寻址 pgd 转换为 物理地址
2.1.1 ARM架构内存映射简介
ARM 架构支持一级页表映射,也就是说 MMU 根据 CPU 发来的虚拟地址可以找到第 1 个页表,从第 1 个页表里就可以知道这个虚拟地址对应的物理地址。一级页表里地址映射的最小单位是 1M。
ARM 架构还支持二级页表映射,也就是说 MMU 根据 CPU 发来的虚拟地址先找到第 1 个页表,从第 1 个页表里就可以知道第 2 级页表在哪里;再取出第 2 级页表,从第 2 个页表里才能确定这个虚拟地址对应的物理地址。二级页表地址映射的最小单位有 4K、1K,Linux 使用 4K。
一级页表项中的内容,决定了它是指向一块物理内存,还是指问二级页表,如下图:

二级页表项的内容:

(1)一级页表映射过程
一级页表中每一个表项用来设置 1M 的空间,对于 32 位的系统,虚拟地址空间有 4G,4G/1M=4096。所以一级页表要映射整个 4G 空间的话,需要 4096 个页表项。
第 0 个页表项用来表示虚拟地址第 0 个 1M(虚拟地址为 0~0xFFFFF)对应哪一块物理内存,并且有一些权限设置;依次类推。
使用一级页表时,先在内存里设置好各个页表项,然后把页表基地址告诉 MMU, 就可以启动 MMU 进行地址映射,如下图:

使用虚拟地址的 index 部分寻址页表,在页表项中找到该页面的物理基地址,然后将基地址和 offset 拼接就得到了物理地址。
(2) 二级页表映射过程

使用 vaddr[31:20] 寻址一级页表,得到二级页表项的物理地址,将二级页表从磁盘中取出放入内存;然后后面的过程与一级页表映射过程类似。
3. 给 APP 新建一块内存映射
3.1 mmap 调用过程
从上面内存映射的过程可以知道,要给 APP 新开劈一块虚拟内存,并且让它指向某块内核 buffer,我们要做这些事:
- 得到一个 vm_area_struct,它表示 APP 的一块虚拟内存空间:APP 调用 mmap 系统函数时 ,内核就帮我们构造了一个 vm_area_stuct 结构体。里面含有虚拟地址的地址范围、权限。
- 确定物理地址:你想映射某个内核 buffer,你需要得到它的物理地址,这得由驱动程序提供。
- 给 vm_area_struct 和物理地址建立映射关系
APP 里调用 mmap 时,导致的内核相关函数调用过程如下:

3.2 cache 和 buffer
使用 mmap 时,需要有 cache、buffer 的知识。下图是 CPU 和内存之间的关系,有 cache、buffer(写缓冲器)。Cache 是一块高速内存;写缓冲器相当于 一个 FIFO,可以把多个写操作集合起来一次写入内存。
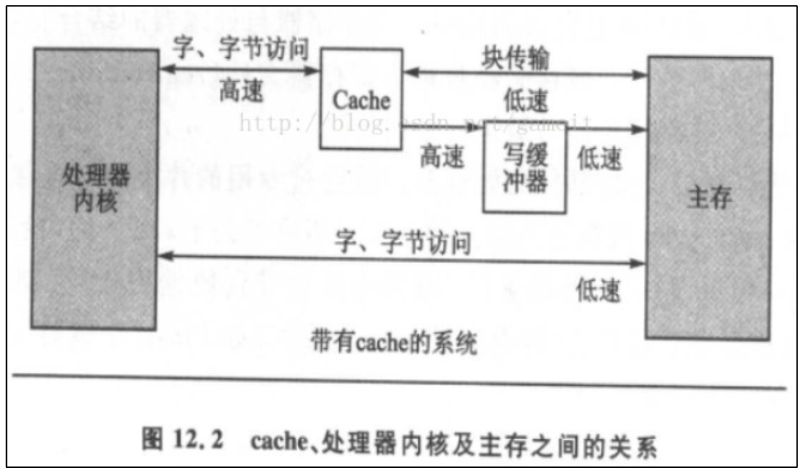
基于局部性原理,为了提高内存数据的读写速度,在内存和CPU之间引入了 cache 。引入 cache 之后读写内存的变化:
读取内存 addr 处的数据:
先看看 cache 中有没有 addr 的数据,如果有就直接从 cache 里返回 数据,即 cache 命中。否则,从内存里把一个 cache line 大小的数据读入 cache,基于局部性原理 CPU 很可能会再次用到这个 addr 的数据,或是会用到它附近的数据。
写数据:
CPU 要写数据时,可以直接写内存,这很慢;也可以先把数据写入 cache, 这很快。但是 cache 中的数据终究是要写入内存,有 2 种写策略:
- **写通(write through)**:数据要同时写入 cache 和内存,所以 cache 和内存中的数据保持一致。但是写内存很慢,因此可以选择引入写缓冲器,写缓冲器有“写合并”的功能,比如 CPU 执行了 4 条写指令: 写第 0、1、2、3 个字节,每次写 1 字节;写缓冲器会把这 4 个写操作合并成一个写操作:写 word,从而提高了写内存的效率。
- 写回(write back):新数据只是写入 cache,不会立刻写入内存,cache 和内存中的数据不一致。新数据写入 cache 时,这一行 cache 被标为“脏”(dirty);当 cache 不够用时,才需要把脏的数据写入内存。
是否使用 cache、是否使用 buffer,就有 4 种组合,参见 arch\arm\include\asm\pgtable-2level.h
1 |
上面 4 种组合对应下表中的各项:
| 是否启用 cache | 是否启用 buffer | 说明 |
|---|---|---|
| 否 | 否 | Non-cached, non-buffered (NCNB) 读、写都直达外设硬件 |
| 否 | 是 | Non-cached buffered (NCB) 读、写都直达外设硬件; 写操作通过 buffer 实现,CPU 不等待写操作完成,CPU 会马上执行下一条指令 |
| 是 | 否 | Cached, write-through mode (WT),写通策略。不使用 buffer,写会直达外设硬件 |
| 是 | 是 | Cached, write-back mode (WB),写回策略。写操作通过 buffer 实现,cache hit 时新数据不会到达硬件, 而是在 cahce 中被标为“脏”;cache miss 时,通过 buffer 写入硬件,CPU 不等待写操作完成,CPU 会马上执行下一条指令 |
- 第 1 种是不使用 cache 也不使用 buffer,读写时都直达硬件,这适合寄存器的读写。
- 第 2 种是不使用 cache 但是使用 buffer,写数据时会用 buffer 进行优化,可能会有“写合并”,这适合显存的操作。因为对显存很少有读操作,基本都是写操作,而写操作即使被“合并”也没有关系。
- 第 3 种是使用 cache 不使用 buffer,就是“write through”,适用于只读设备:在读数据时用 cache 加速,基本不需要写。
- 第 4 种是既使用 cache 又使用 buffer,适合一般的内存读写。
3.3 编写 APP 测试程序
mmap 函数的原型如下:
1 |
|
各参数的描述如下:
- addr:指定映射的虚拟内存地址,可以设置为 NULL,让 Linux 内核自动选择合适的虚拟内存地址。
- length:映射的长度。
- prot:映射内存的保护模式,可选值如下:
- PROT_EXEC:可以被执行。
- PROT_READ:可以被读取。
- PROT_WRITE:可以被写入。
- PROT_NONE:不可访问。
- flags:指定映射的类型,常用的可选值如下:
- MAP_SHARED:与其它所有映射到这个文件的进程共享映射空间(可实现共享内存)。
- MAP_PRIVATE:建立一个写时复制(Copy on Write)的私有映射空间。
- …
- fd:进行映射的文件句柄。
- offset:文件偏移量(从文件的何处开始映射),该值必须是
sysconf(_SC_PAGE_SIZE)函数返回的页面大小的倍数。
返回值:
成功时返回映射区域的虚拟地址的指针,失败时返回 MAP_FAILED
1 |
mumap() 函数原型如下:
1 | int munmap(void *addr, size_t length); |
该系统调用删除指定地址范围的映射,并导致对该范围内地址的进一步引用生成无效的内存引用。进程终止时,区域也会自动取消映射。另一方面,关闭文件描述符并不会取消映射该区域。
返回值:成功返回 0,失败返回 -1
3.3.1 MAP_SHARED 和 MAP_PRIVATE 的区别
使用 MAP_PRIVATE 映射时,在没有发生写操作时,APP、驱动访问的都是同一块内存; 当 APP 发起写操作时,就会触发“copy on write”,即内核会先创建该内存块的拷贝,APP 的写操作在这个新内存块上进行,这个新内存块是 APP 私有的,别的 APP、驱动看不到。
MAP_PRIVATE 映射是很有用的,Linux 中多个 APP 都会使用同一个动态库, 在没有写操作之前大家都使用内存中唯一一份代码。当 APP1 发起写操作时,内核会为它复制一份代码,再执行写操作,APP1 就有了专享的、私有的动态库,在里面做的修改只会影响到 APP1。其他程序仍然共享原先的、未修改的代码。
仅用 MAP_SHARED 参数时,多个 APP、驱动读、写时,操作的都是同一个内存块,“共享”。
3.3.2 APP 代码
1 | int main(int argc, char **argv) |
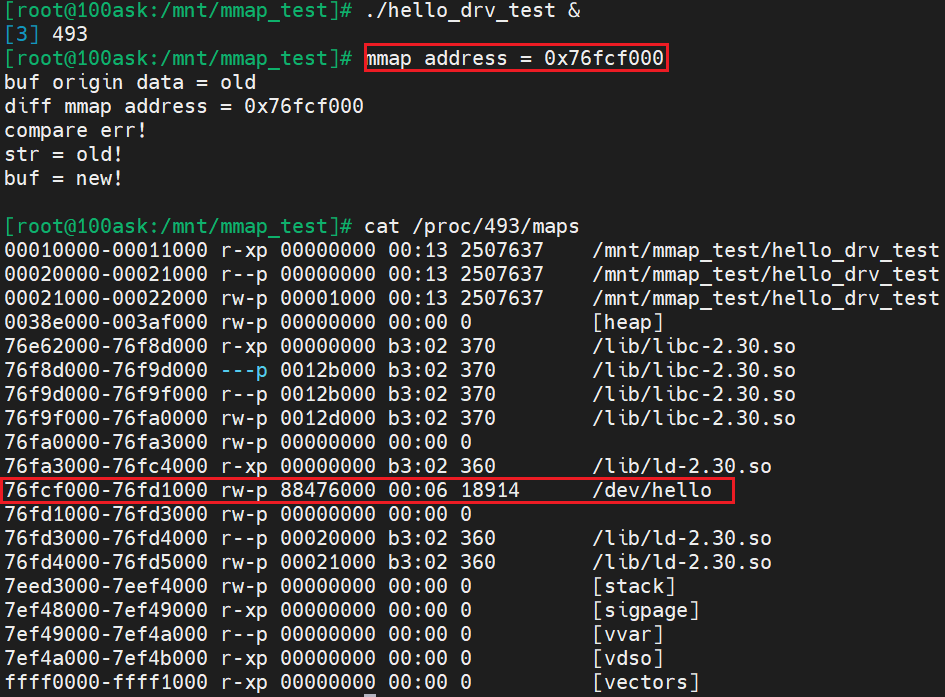
运行 APP 后,查看该进程的内存映射信息,可以看到驱动为其分配的内存对应的数据段:
3.3.3 驱动编程
在驱动程序中提供 mmap 支持,需要分配一块内存,并在 file_operations.mmap 函数中建立 APP 虚拟地址到这块内存物理地址的映射。
分配内存使用的函数:
| 函数名 | 说明 |
|---|---|
| kmalloc | 分配到的内存物理地址是连续的 |
| kzalloc | 分配到的内存物理地址是连续的,内容清 0 |
| vmalloc | 分配到的内存物理地址不保证是连续的 |
| vzalloc | 分配到的内存物理地址不保证是连续的,内容清 0 |
我们应该使用 kmalloc 或 kzalloc,这样得到的内存物理地址是连续的,在 mmap 时后 APP 才可以使用同一个基地址去访问这块内存。(如果物理地址不连续,就要执行多次 mmap 了)。
在安装内核模块时分配内存:
1 | static char *kernel_buf; |
在卸载模块时释放内存:
1 | kfree(kernel_buf); |
file_operations.mmap 函数的编写如下:
1 | static int hello_drv_mmap(struct file *file, struct vm_area_struct *vma) |
宏 pgprot_writecombine 的定义如下:
1 |
设置不使用 cache, 使用 buffer。函数 remap_pfn_range 的定义如下:
1 | /** |
注意:pfn 表示 page frame number,因此需要将物理地址 phy 除以页面大小,得到对应的页号,即 phy >> PAGE_SHIFT